I strongly recommend reading carefully the story behind how this guy could build his own HFT firm. It’s a fascinating story.
Source: https://meanderful.blogspot.com
I started my HFT career at one of the larger American trading firms as a C++ jockey. On my first day, I was greeted by full panes of glass boasting glorious Sydney Harbour views which were modestly obscured by a hand-scrawled “< 2ms” on that glass. This was the main goal for the dozen of us in IT. That wasn’t my remit at the start though. First things first…
Early daze
One of the desk guys had an idea for trading tailor-made combinations on the Australian Stock Exchange (ASX). That is, equity option spreads and combinations, along with their associated hedges. He needed something that could handle a bunch of intricate auto-trading rules that could be integrated with the Orc front-end being used for ASX trading. It was the early 2000s, so I developed a quick resizing UI with VB6 for the Windows 2000 desktops. This involved C++, Boost, multi-threading with a Spirit parser for the Orc integration at the back end. Orc calculated the binomial or trinomial trees for the ASX-listed American options on demand. For my binomial pricing code, I used simple Haug VBA code that I had transliterated to C++.
However, Orc didn’t calculate solely on demand, rather it used simple memoization for pricing. If the parameters were the same, Orc remembered, rather than recalculated the price. Our Orc Trader had been too slow to beat Timber Hill’s custom platform or IMC’s exclusively-licensed Orc Liquidator, the fastest vendor system at the time. The stack seemed too lame to be latency competitive, no matter what tricks I could come up with. However, with a large price cache from the busy C++ threads diligently filling out a multi-dimensional cache of option prices by parameter proximity for easy interpolation, suddenly we could hit trades that were previously unhittable.
By changing an interest rate, or selecting another volatility curve adjustment in Orc Trader, my pricing cache got busy replenishing itself. This wasn’t an entirely original solution. I first heard about the idea of pre-caching option prices in an old article about either Hull or CRT some years prior. Just as a modern out-of-order microprocessor can speculate on the next thing that’s going to be required, so can you. Market prices are discrete after all. Remember, the fastest calculation is always the one you don’t have to do. A later lesson was it was hard, but not impossible, to beat zero latency. This strange corollary to this speculative lesson exists because the fastest message is the one you don’t have to send. This is perhaps even more significant.
In my view, the best architecture is no architecture. That is a little facetious, but an important system truth. Reification just becomes legacy without a sufficient lack of architecture. As premature optimisation is the root of all good, it is best to not talk too loudly about computing myths as it is best for your competitors to stumble.
The Orc Trader hackery I concocted wasn’t a great solution, but it made a few people happy getting some trades that were previously out of reach. Indeed, there was a bit of fist pumping and mirth when they first got some types of trades they’d never seen before. Overall, it was only mildly successful. It grew to hundreds of manual rules monitoring trading potentials and seemed to pay for itself when someone bothered to turn it on. It was a fun build for me at least.
Focus on “< 2 ms”
Let’s revisit that “< 2ms” challenge on the window. I wrote a paper espousing a faster, but more complicated way of getting much lower latency. A three-person team, myself included, was born to go and try. Korea was the first choice. No need for option pricing caches in this project, even at a secondary level, as the European index option calculations, especially the incremental or finite differenced ones, are not that much more expensive than a cache interpolation, even on limited dimensions.
This was a time in which 2-3 GHz processors were new. Our performance measurement approach was a bit lame. We measured performance internally within the application rather than properly from the external network. This was fine when talking about two millisecond time frames as the network stack was in the 50 to 100 microsecond zone in those days of yore. The key point to remember here is that when you can do more than a billion instructions a second, that translates to more than two million instructions for two milliseconds. Frankly, it was just criminally wrong that even a millisecond, over a million instructions, was burnt on simple trading tasks. If it takes you a million sequential steps to decide on a trade, retire now! A modern processor can do thousands of instructions in a microsecond. Every nanosecond is sacred.
As a relative newbie to a firm, you have to tread carefully when you get assigned to a non-functioning team. In the development phase, there were only three of us, including me. One team member, who was normally excellent, unfortunately rebelled by spending time focused on inter-webs, games, and forum posts about GPU cards. Mr. GPU had previously written the firm’s core libraries for multi-threading, which were quite good, but strewn with nomenclature errors. Mutexes were locks and locks were mutexes. I ended up choosing to use Boost’s C++ libraries just to stay sane. Mr. GPU didn’t seem to enjoy the project and kind of went on strike, it seemed. Part of it was no doubt being annoyed at having to work on my newbie idea. The other guy was less capable, but not incompetent. He would usually eat a lot of food and zone out to watch DVDs.
We had to get on with it. Two milliseconds to beat. As it turned out, I had more code than expected to write – hence a few late nights and stumbling over bumps in the night. Mr. GPU did end up doing some integration work on the edges, while Zoned-Out Guy did no work at all. The result was a system a bit faster than five microseconds. I thought that was a success. The speed did not take into account the network stack. Clearly, the network stack latency now mattered a lot more than it did a month earlier.
One of the other IT guys congratulated me and from him I learned that the majority of the IT team, including him, thought it had been an impossible task. Apparently, most were also hoping I’d fail. It appears change coming from the new guy was not widely appreciated and I only received a small bonus and no significant pay rise.
I had hoped to stay in this job for twenty years, especially after that dot-com bubble thing. Plainly it was time to move on for me.
Finding a new job
I chatted to a few firms and shared some new thoughts on how to do things. One private trading firm, one of the good Dutch firms, listened intently but nothing happened. Years later, I learned that a team started implementing some of what we had talked about in those interviews the very next week. I heard the approach was successful. They called it the “implied base method”, where everything is expressed in terms of a base future or instrument. I liked their name for my technique, although it all sounded a bit cargo-cultish to me. This is pretty much how a modern delta one desk thinks about life. I was flattered to be deceived.
I then spoke to a significant Australian institution that had a team of around a dozen developers focusing their holy dollar on the ASX market. Their technology was even slower than Orc Trader, most of the time, with significant milliseconds in their stack. I arranged a meeting with the business head, who was a lot more successful and much younger than me. He was one of their high-income earners whose income has to be declared under Australian listing rules. The politics of the business looked untidy and he warned me that earning money overseas wasn’t easily attributable back to your profit centre. The discussions with this firm was a waste of everyone’s time – I don’t do black hat. Grey is fine. Finding gaps between the rules is a fun game as long as the ethics are acceptable. However, those black lines should not be crossed. There is no fun in winning by cheating but, more importantly, reputation matters. People always underestimate the NPV of a scandal, and I did not want to risk that.
One investment bank that I spoke to, I liked. It was a big Wall Street firm’s outpost. I had spent years in that kind of environment previously. The pass bar seemed pretty low. They didn’t want to make money. They just wanted to generate no-cost turnover so their corporate finance department could serenade firms. That was looking the best option and I was sure they wouldn’t mind getting their turnover and also making a profit. Profits rarely cause complaints.
A good thing about my prior firm is they did fire people for making money. Someone broke the rules by doing some pair trades they were unauthorised to do. They made money. I was impressed they were fired for breaking the rules. Such a correct stance is shamefully all too rare in financial services.
Then another opportunity popped up quite unexpectedly.
I had lunch with a guy I knew from my computer sciences course at the University of Tasmania, who now worked for ITG. He suggested I speak to ITG, as they did proprietary trading. That was news to me; I had thought they were just a broker. I met their Asia-Pacific CEO and he filled me in a little more on their dual-listed arb machine that was running on USD and CAD stocks. Then I met the US CEO, Ray Killian, when he was on a trip to Australia. The meeting went alright and there seemed to be a lack of resistance for doing more HFT-style trading at ITG. The Asia-Pacific CEO plus their chairman, who was also a board member of the NYSE-listed ITG Inc., eventually took a makeshift business and risk plan to the US for a board meeting.
Then I don’t really know what happened next. I was told three quite different versions over the next few years. According to one version, the board approved it, but Killian knocked it back. According to another version, some board members did not approve the plan. Another version had it not going to the board at all. I’m later not sure which versions were false, perhaps all of them. It didn’t matter. The ITG guys decided they would bypass their employer and invest personally. It was not quite the new job I had planned, but if the business went well, I could earn about a quarter of the new company’s shares via options vesting over a few years. It felt like a win.
A new HFT firm is accidentally born
So with a 1.5 million AUD investment, it was time to start working again, all by myself with a laptop in a serviced office. I built some servers, desktops, installed Suse 64-bit Linux, hired three programmers – and the funding runway clock started ticking. It turned out I’m not a very good Linux system administrator. Not many months later I tired of doing system-administration badly and got some part-time help. Our head-count was now four and a half. But 64-bit Linux, especially with AMD & Hypertransport, was not ready for prime time, so we dialled back to 32-bit and Redhat / CentOS. It is a wise call from Mr. Sysadmin and progress improved.
Four months in, things were looking prospective. We had tossed and turned on starting locally on the ASX or going to Korea. The Korean exchanges: KSE, KOSDAQ, and KOFFEX, were merging into the Korea Exchange (KRX). We decided on Korea even though the business and tech environment was more complex and riskier. At the time, the opportunity was larger, plus the math and the limited number of products promised a simpler code base.
A funny thing happened about then. When building a new system, you try to set some naming conventions to future proof yourself a little. I decided to use ISO codes, or part thereof, for the exchange names. However, due to the merger of the Korean exchanges, there was no ISO code for the Korea Exchange. I contacted the ISO group responsible, which turned out to be one guy with a spreadsheet somewhere in Europe. He decided XKOX would be the new code for the combined exchange. I gasped and wrote back suggesting this would have an unfortunate English phonetic symbolism. Perhaps the obvious KRX, or XKRX in their nomenclature, may be a better idea? There was a joint laugh over email and XKRX became the ISO code. I think I can claim I originated the ISO code for the KRX.
In those old times in Korea, traders, even HFT ones, didn’t get access to the exchange directly. You had to go through a broker gateway and use their broker specific API to connect. There was no co-location. A great deal of the variation in performance, beyond a broker’s control, was simply due to the location and exchange-provided technology. Now, the KOFFEX was the futures and option trading bit. KOFFEX was based in Busan, a seaport town a little over 300km away from Seoul. The KOSPI 200 products were small in ticks but large in volume. They were the most popular derivative contracts in the world by around a factor of nearly ten back then. Eurodollars at CME were number two and K200 options were number one in volume. This had proved a bit too much to handle for KOFFEX. They had the K200 market run, on their behalf, by KSE in Seoul. So everything we needed was in one location in Seoul, although the primary derivative platform was based in Busan.
Now, I was aware that the network stack was perhaps the most important latency aspect I could control in this implementation. I found a hardware device that could do a three-microsecond translation from InfiniBand to Ethernet IP. It was a module that would plug into a TopSpin InfiniBand switch. Hypertransport (HTX), an alternative to PCI Express (PCIe), was a new thing in AMD land and it provided a lower latency way of doing InfiniBand comms. I bought some Pathscale HTX Infinipath cards, HTX mainboards in alpha (e.g. serial number 0x0000045!), boxes, plus assorted bits. I assembled up a motley crew of parts to be a gee-whiz, not dirt cheap, but extremely frugal, network stack. It felt good. I had my somewhat clumsy but world-competitive network stack. It would not be for some years that regular network cards could spank that set-up.
Choosing a broker
We were off to Seoul to find a broker and data centre location. I went with one of the investors, Bubble, who would come on as a staff later. At first, he would split his time between ITG and the HFT. He could get away with this abuse as both the CEO and Chairman for Asia-Pac, plus other ITG staff, were investors. Unfortunately, Bubble booked the hotel in Seoul. It turned out to be a “love motel” booked from a very picturesque artistic impression rather than a true picture. Seedy, unclean, rooms with flaky air-conditioning unsuited to the humidity. A virus-infested Internet PC. Not a great start. A couple of brokers picked us up and expressed a bit of astonishment at the locale. Embarrassing but funny. It turned out to be a quite productive trip. We got a ground shaking, unbelievable deal.
A good deal
Muppetz Securities offered direct exchange access. The big firm I had left didn’t have direct access. In fact, I had priced getting an HP/Compaq/Tandem non-stop system in the old job as it was one way of getting into a particular broker’s production network to be closer to the exchange. It was about 500,000 USD for a small dev box on a special HP application development program. Tempting, but not taken by the business at the end of the day. So, this offer of direct access, which was X.25 serial access, was groundbreaking to me. The broker’s deal was kind of expensive, but, as direct access was unheard of back then, I signed the contract after a few days.
At the time, I ran into Mr. Ree from RTS, who was in Seoul sorting out some business. We were helping each other in approaching brokers. We used RTS as a backup repository for our trades so the shareholders would have some comfort that a third-party vendor system could price things independently. You may think the logical choice was Orc. I was familiar with Orc and it had kind of won the trader user interface game at that stage. However, RTS had a much nicer API and was around 10% of the monthly cost for what I needed.
Back in Sydney, I looked at all that expensive TopSpin InfiniBand gear. It was now useless to me. We were going X.25. An unexpected but pleasant turn of events. Then I received the message from Muppetz. The deal was off. The signed contract was worthless.
Quite sometime later I learned that Muppetz had gone to the big firm I’d left. X.25 was a limited and rare resource. Why give it up to some little wannabe HFT firm that had never traded, when you could go to their past employer and get a real trader to bite the hook? It was a smart move by Muppetz, albeit unethical.
It turns out saying “no” had loosened some brokers’ thinking. Many HFT firms were thinking about how to get direct, I presume. The time must have been ripe. The annulment of the Muppetz contract led to much better offers. One from Mr. M., the gentleman, an awesome guy with a good team, was shockingly good. The pricing was much better than Muppetz and not so dissimilar to indirect access from elsewhere but the location was stunning. It was in the exchange building!
I had no idea people were allowed to trade there. It turns out this firm had a dusty, plain room with no air-conditioning in the old KRX Annexe. This old Annexe, as opposed to the new Annexe just being completed on the campus, was connected by a corridor to the main tower that housed the exchange matching engine a few floors underground. This room was used for the broker’s disaster recovery. It had a thin desk in a narrow room with emergency terminals with CRTs. If the world came to an end, you’d send your staff in to punch keys there. It was not really spec’d for infrastructure. Would we be interested in this little lame room as it was the best they could do for now? It was all I could do to negotiate a deal without appearing too excited.
The Muppetz solution was X.25 but from their building off the KRX campus. Someone was going to be paying a premium for a solution that wasn’t quite as hot as the one we’d just landed.
X.25 and technology
X.25 as part of the exchange infrastructure was interesting. You had T1 or E1 lines, they did both and sometimes you got one of each, from Koscom, the KRX technology and communications provider. The lines had virtual circuits of 64 kilobits per second (kbps) on them. Interestingly, as the T1 or E1 channels were interleaved, you have parallel access to all of those channels at the same time. A broker had a limited number of lines but many parallel, albeit slow, channels.
I did a bit of research and bought X.25 cards from a vendor in the UK. Popular enough, decent references, and they seemed of industrial quality. I’d written a car lease processing system many years prior at Citibank that was X.25. The games I had to play with the car leasing stack was only really possible as I had a misspent youth in the pre-Internet days of BBS, FIDO, z-modem, y-modem. Much of the Citibank experience was playing modem and hardware games to just get things to talk. Once talking, everything was simple. Not so much with these cards. Neither us nor the card vendor could get them working properly. We eventually raised our voice and the vendor just ghosted us. We then bought some cheaper cards from a Canadian company called Sangoma. They worked very well.
In our dusty DR room, we had a rack put in. I went up with my hand-assembled servers in luggage. There were no exchange lines for us yet. Order lines would come a bit later but we urgently needed market data to groom and tune our approach. HFT needs lots of data. The exchange solved that by running some twisted pair outside of the building and in through a hinged window in the DR room that we had to prop open. Not too much water would get in when it rained. The twisted pair plugged into some T1 modems. The T1 modems plugged into serial line providers. Giant X.25 connectors, escapees from the 1960s, plugged into our Sangoma cards. Slow bits are big bits.
Order lines with more giant X.25 connectors came along. We had some Postgresql services (soon replaced by flat files), a C++ trading engine, a volatility publisher, et cetera. Instead of using leased lines, as was the convention, we used regular internet lines. We’d take three vendors that promised geographic independence and mapped the routes to ensure diversity. Much cheaper, better bandwidth, and more reliable than leased lines. This was unusual at the time but many do the same now. I had been burnt working at other companies with promises of redundancy on leased lines that turned out to be false, so this kind of solution, that you could control, suited me better.
(False) start of trading
Nine months into the launch, we had finished the testing. No certifications were required. It really was the land of cowboys back then. We started trading – 85% hit rate on the options! That either meant you can’t price options, as anyone would give you adversely selected bad options, or you are doing well. It was mainly the latter.
But we couldn’t make money.
The plan had been to simply take juicy options and hedge with the futures. We’d spent nearly a million dollars on getting this far and the leftover balance of half a million was required by the prime broker for our trading and couldn’t be touched. We could get decent edges alright, but the profit would evaporate before we could hedge properly. We worked on this and it improved a bit, but we could not get it resolved. I was sleeping in the office and the rest of the team was also working hard. The performance of the trading engine wasn’t up to scratch. I bit the bullet and rewrote it over a 72 hour period. It was much better afterwards, but we found a bug in the new trading engine. Internal app latencies masked it but it showed up on external measurements. A logging thread was being followed instead of the main thread and it was costing us a lot of time. A proper resolution would not be completely simple as we’d have to rip out the condition variables. I just chose to move the threading to real-time threads with appropriate cascading priorities and… tada: job fixed. Though it was a bit of a hack, we now had a consistent double-digit microsecond response time.
Getting the implied volatility (IV) curve right was a bit of an art. Back at the old firm, the traders had used a manual IV process where every five or ten minutes, or hour, they’d adjust their curve to fit the market. A clever quantitative trader there eventually built a neat and robust automated way of doing that. Here I also wanted the IV fit completely automated but chose a different approach. Using similar quadratic curves didn’t suit me as it often led to an uncomfortable discontinuity at-the-money. We used a more normal spline fit with embedded R, added some small median filters, and some other statistical hocus pocus. We published IVs every second. Later we would sometimes publish every quarter or half second but every second was enough back then. It improved things. The pricing was seemingly tight. Generally, we’d make no money or very little. Time and its operating cost was killing us, not trading losses.
We did have one screw up that was notable. Mr. L. made some changes to the futures hedging that we rolled out. The second we turned it on, it bought and sold about a thousand separate one-lots in futures at the same price in a few seconds. We had to kill it off immediately. The company could have died right then, but we had a lucky escape.
We kept trying… but we still couldn’t make money. It wasn’t the latency. The pricing wasn’t terrible. Our futures hedging was simply not efficient enough. We didn’t have the capital to paint the levels and use that improve our P/L. We tried passive making on the futures before hitting the options, but it was unimportant. Nine months had passed, gestation was complete and sleeping in the office was having diminishing returns. It was time to pray.
Strategy Zero
When you trade you’re lucky if you gain a fraction of the spread. At the time in Korea, the ATM options and those cheaper had a tick size of 0.01 price points. That 0.01 was worth about a dollar. Churn a lot of options at HFT speed and, if you’re lucky, you come out with ten or twenty cents of the dollar spread on average. One of the goals here was to exceed what I’d seen done in the past. The record at the place I’d left behind was 1.13 million option contracts in a day I think. If you could do a million options and take 10 or 20 cents for each, you’d be pretty happy. In theory, there is no difference between practice and theory. It was proving difficult for me.
Then I remembered a conversation one of the traders, Mr. B., at the old firm, who did end up leading the firm eventually, had with someone in the kitchen. Mr. B. was asked if he bought an edge and it had value, why didn’t he just sell it back? He dismissed the enquiry, claiming that if it was that simple, he’d make a lot more money than he was. We had a great latency edge with the location and direct X.25. The tech was performing. Our pricing seemed keen enough. Maybe we could do the impossible?
I talked to the shareholders and told them I needed an extra 25,000 AUD to survive the month to try something new. The main investor issued a loan of 25,000 AUD. Mr. F., one of the original hires, coded what we called Strategy Zero. It was simple: have no position, wait for an option edge of a reasonable size, at least a tick. Then, hit it. Wait. Dump it out and take a tick profit. Would it work?
Survival!
Trading income went to a healthy six figures for the month. Strategy Zero worked. We scaled up so we would trade 500 or 1,000 ATM options at a hit and then turn around and dump them straight back. No clever market making here. We were just being an aggressor.
Being an aggressor in a market can be more problematic than making. As a market maker, you have to dive out of the way when things go against you, but you need to be stoic enough so you don’t get too flighty and lose valuable queue priority. Generally, the threshold to bail and avoid adverse selection will be lower, in terms of pricing edge, than the aggressor who chases a pricing edge. It is a strange game that the aggressor is effectively handicapped in latency terms as they are only prepared to move after a maker would have already moved, all other things being equal. It’s like a 100m sprint where the maker has a lead of 50m and you have to somehow chase them down. That pretty much describes Strategy Zero. Direct X.25 connectivity and an on-campus location with wires coming through a window fixed ajar into a room with no air-conditioning was enough to overcome our strategy naivety in those early days. Fortuna smiled.
There was some joy in transferring some profits home and seeing money turn up in the bank account. It felt a little surreal. Trading index options in Korean in Won and having Australian dollars turn up in a bank account in Sydney. Some of the new coin went to a homebrew cluster in our dodgy newly-leased 200 square metre Hunter St. office. Mini-ITX boards sitting on a cheap storage rack, some sticks of RAM, loose ATX power supplies and a switch. IV modelling, simulations, and strategy all improved with a few hundred extra cores working on it.
The next main step in trading strategy was going from Strategy Zero into a proper trading strategy with hedging. Instead of trying to hedge with futures we turned to hedging with other options. We didn’t want to hold positions overnight but were happy to hold them during the day. Strategy Zero would only clock up seconds of exposure during a day. The new evolution had us with positions all day. It worked very well. About two-thirds of the KRX market were low delta options with fairly static pricing. It wasn’t unusual to see over a million on the bid or ask in the teensy options. Get those low price options and they were hard to shake out before market close. We just focused on the tighter priced options with larger deltas, those with 0.01 sized ticks with prices under 3.00. This represented around a third of the market’s trading volume. We eventually grew to around a typical 6-7% market share with the occasional day over 10% market share. Strikingly, this was around a third of the market we were focusing on. Quite some piece of the pie. Bypassing the old volume record at my previous firm felt good.
Tapping the wires
The first significant hack came from considering those twisted pair cables that came in through the window. The T1 and E1 modems turned those twisted pairs into clunky connections going into a larger network device that then had huge connectors for plugging into the serial cards. A bit of research and the obvious plan was hatched. I bought some new Sangoma cards that took the twisted pair and grabbed some NetOptics T1/E1 taps. I casually installed the taps and cards in Korea. When asked what they were for I said for line status monitor and latency measurement. This statement was technically true but also incomplete.
The new Sangoma cards supported a transparent bitstream approach where it just dumped the raw bits out on a channel you could slurp. I started hacking away and figured out what the streams looked like. X.25 virtual channels were grouped into data feeds for market data. They tended to be consecutive. There was a different channel group for puts, calls, and futures. I had to hack up a brumby HDLC layer but before long I had packets corresponding to the KRX feed. Bypassing the modem and network device saved about a millisecond.
This wasn’t unfamiliar territory. Eurex, when it had the old Values API, provided by a box, people hacked around it and reverse engineered the protocol. A formal Technical Member Regulation document was adjusted to make that against the exchange rules. The practice was stopped. There was no such rule in Korea. Similarly, when the ASX opened its first small co-location in Bondi Junction, I noted a couple of firms had taps around the exchange provided 1U Dell server gateways. Reverse engineering the Nasdaq ring protocol wasn’t as uncommon as I had imagined; there are lots of clever hackers out there.
Slice and dice
Things got even better for us in Korea. Now that I had the bits streaming off one by one, or at least byte by byte, you could see that the packets took a long time on the wire. Milliseconds. A common technique in network monitoring is slicing, where you just take the first part of the packet. I did this with the HDLC bypass code and we were now a long way ahead of the game as the bid and ask fields were at the front of the quote packets. Save 100 bytes at 128 kbps and you’re 6.1 milliseconds ahead. As specifications changed and KRX feeds sped up, our advantage reduced but life remained good. Now we were sending out orders before the data packet arrived.
Occasionally the exchange would change the placement of the virtual circuits and we’d be left with a slow feed until I unscrambled the new positioning. Infrastructure improved. We now had cables not going through the window but coming from the building’s main distribution frame. A small air-conditioning unit was installed above the window which was much needed as things were getting seriously hot. The DR closet room was not a proper data centre. The bank we were broking with then sold their equity derivatives business. After a short while, the new owner classed us as a non-essential client and told us to get out of our office. I later learnt the new bank that bought this business had an AI trading group in Tokyo that wanted our room for themselves.
Dumped
We were dumped on the spot over Christmas and had to scramble to find a new home. We focused on finding more than one home, so the business would be a little more resilient. Direct X.25 was not common, but no longer unusual. Someone called Dr. S. came to the rescue and Mr. L. had our gear shipped, or wheeled, to their data centre room across the road. This broker was a bit smarter and understood that if we were tapping lines then we could potentially see orders flowing the other way. They were right, we could, but weren’t doing that yet. We had to get a separate infrastructure for our own market data set-up. The broker did a great job and we were thankful for the smooth transition. The Muppetz Experience proved to be an exception. Brokers in Korea are good people.
We did the same kind of set up elsewhere and kept on going. We noticed the market data speeds were quite different at different sites. We couldn’t get GPS into the sites but Korea used a CDMA mobile phone system. Endrun Technologies had a nice little plastic box with which you could upgrade the temperature-controlled oscillator and get stable timing. This device syphoned off the embedded GPS signal within the CDMA signal and provided an NMEA serial feed plus a pulse per second (PPS) cable. CDMA is only spec’d to 10 microseconds of jitter, but we were getting around one microsecond of accuracy in Seoul. FWIW, Canada’s CDMA gave us around 5 or 6 microseconds of accuracy.
We did eventually end up with systems in the KRX underground data centre itself. It was quite the security rigmarole to get in. It was a long way underground but I noticed I could get a cell phone signal in the DC. I put a CDMA timer in there too. It worked enough that we got good timing from the intermittent cell signal until something burnt out. I suspected it needed a better antenna as perhaps something was driving too hard. Before a trip to Seoul, I bought a meter long white whip antenna and soldered on an SMA connector. I got into the KRX DC underground bunker and laid the big white antenna on top of our rack. The Koscom guys looked at it suspiciously. I don’t know what they thought, but a surprising number of other people over the years mentioned they had seen my white whip aerial laying on top a rack in the KRX DC.
We now had good timing at the sites and needed to share data. We found that within a couple of blocks of the exchange campus, we were getting 300-microsecond one-way traffic over 10Mb public Internet Ethernet between our sites. That was surprisingly good. We co-ordinated our market data and ordering over those internet lines. Korea has great internet and it was certainly good enough back then. Milliseconds of advantage from consistent market data across all sites improved trading. Whilst our best ordering came from the exchange campus, the best market data came from a couple of blocks away. That was unexpected. It remained the best market data site for a few years.
At one later site in the new KRX Annexe, we put in market data and it was the worst. For what its worth, this was the first place that I knowingly ran into Citadel in Korea. Courier labels tell all. We asked for this market data to be removed. Koscom left the gear and just disabled it. A month or two later we paid for it to be reinstalled. They enabled the same gear without changing anything and now it was one of the best. Such were the vagaries of life in Korea. I suspect some new kind of semi-permanent round robin positioning somewhere fixed things. There was little rhyme nor reason for many things.
The virtual channels on the X.25 for ordering were only 64kbps – very slow. I figured we could hack those similarly with the Sangoma market data stack and starting filling out an order before we had one. This would save us milliseconds. You could turn the packet into something benign or invalid if you didn’t have an order to go. We were pretty busy with a small team and this didn’t get a priority as there was nothing wrong with our hit rate profile. We had more learning to do with IV modelling and strategy.
Change is constant
Exchanges never sit still. The KRX was no exception. They were dumping the X.25 and moving to Ethernet and IP. The KRX planned TCP for order data and UDP for market data. Our X.25 trick was about to evaporate. We’d become gluttonous in our trading engine and strategy. There wasn’t much change out of three hundred microseconds in our trading engine performance now. It had bloated. The guys, at some stage, had taken my 72-hour coding hackathon and turned it into something that was more traditional, simpler, and faster to compile. Strangely we now didn’t care too much about a hundred microseconds here or there as we chased strategic and tactical improvements. We effectively had a negative latency relative to others due to the tapping, device bypass, and HDLC packet slicing. Our orders were still going out before the market data arrived.
We wanted to try the X.25 order speculation but didn’t have the staff to spend a couple of months coding it up, especially given the limited lifespan X.25 now had with TCP looming. A custom X.25 layer would be useless a few months after completion. I had an idea and talked to the guy that wrote most of the Sangoma software. It was largely one main guy who did the bulk of the work there on the device layer. Could he recommend someone? He said he would do it as a side project at home for us. There were some concerns as the source for the drivers was pretty messy with an abundance of jumps or gotos in the C code, but, even so, the drivers worked solidly. It was only for a few months, so it seemed a good risk. It took a little longer than expected, but the schedule slip was not too bad. The order speculation worked but its performance was terrible. The code was sufficiently diabolical that the fast path was slower than a normal path. We had no time to revisit and shelved the idea.
The KRX IP changes were a pretty simple mapping of Virtual Circuits from X.25 onto TCP sessions for orders. You could have multiple sessions, which they called PIDS to send orders on. Market data packets were going from grouped channels to UDP packets. I can’t quite remember if the encryption came immediately with TCP on launch or shortly after. An ARIA cypher was added for the order payload beyond the plain text header and it was to be a requirement. ARIA is the Korean national cypher. It is quite similar to AES in design with a slightly different and slower S-Box arrangement. It’s a good cypher.
We could see this new IP architecture was going to shake up the market and potentially destroy much of the large brokers’ business. The old X.25 was slow but the interleaving of the channels meant that you had a lot of parallel paths for ordering that could be shared. In the new TCP world, there was a limited set of order lines, two or four, and all customers had to serialise through those connections despite there being many PIDs. Customers were about to queue up at the broker. Not only would it be a race to the exchange, it would now also be a race at the broker. Large brokers were about to lose market share as limited lines could only support a limited number of heavy traders. In addition, the order line rate was being increased, the market data packets were getting bigger, and the market data rate wasn’t going to be increased appropriately to keep pace. The exchange was heading for a bit of a mess. We saw we needed to get ahead of this. Time to access more lines, which meant more brokers to connect to.
We went up to Seoul and had a look at the set-up. We got some copies of architectural diagrams that Koscom had helpfully taped to cabinets at various brokers. It was showing a 622Mbps city ring back-bone with links coming into brokers. In the cabinets, we saw our old friends the T1 and E1 modems. This was very good news; we could continue to use the same tricks for our market data. The new set-up had the T1 modems dumping into devices that fed relatively low-end Cisco switches. If we tapped the copper T1 twisted pair lines after the main communications cabinet decoded the fibre optic feed, we’d be fine.
The transition to TCP was a little messy for the KRX. All the things we expected came to pass. Large brokers, such as Samsung Securities, lost market share as they had just been shafted by the KRX on their ability to effectively serve their large base of customers. Market data delays became de rigueur as the exchange took orders faster without commensurate market data capacity increases. We were already handling those delays well. We used the embedded exchange timestamps to track delays in the market data. The puts, calls, and futures arrived on different feeds and typically only one, or sometimes two, would be delayed. We sensed the latency imbalances and switched to hedge-only mode. Many times we thought of taking advantage of the situation, as we knew others would be hamstrung with skewed market views, but it was never tasked. Sometimes the feed imbalances would have severe delays, with data lagging behind tens of minutes. Once the imbalance cleared, the engines would automatically go back to trading.
Tapping the lines was interesting. It was not against the rules as I don’t think it had ever been contemplated. The move to IP instead of X.25 had introduced mandatory firewalls. We learnt some traders, local ones, were bypassing the firewalls. This was against the rules and something we were not prepared to do. Break an explicit rule and you may get kicked out of the KRX entirely. The KRX had no policy on how to come back if we ever got banned. The decision could be final. We calculated our advantage was much greater than the firewall cost, so, as long as those groups weren’t tapping and slicing, our advantage was safe and the firewall bypass guys were barking up the wrong tree. Only recently, I learned of another local group trading beyond the firewall in Korea. So it still happens, but it is rare now.
FPGA hacking
We also succeeded in improving our market data hack. We were a small firm with too many people named Thomas. It’s a bit convoluted but the eighteenth hire was our sixth Thomas. Part of the problem was because of me: I was aware of the Thomas problem and, for fun, was looking at postgraduates named Thomas at various places. I noticed a Thomas at UNSW in their NICTA group. He was doing a PhD and had done some interesting work in distributed shared memory on Linux including Itanium. I was familiar with it, after I had done an Intel course on one of the original Lion servers. I reached out and he started working part-time for me as he completed his PhD. One of the cool things he did was hack the Sangoma cards we were using. Those cards used a fairly small Xilinx FPGA, a Spartan 3, to do most of their work. He hacked a firmware register twiddler into the FPGA and found some registers we could drive. Before long we had our own working firmware and could bypass the Sangoma firmware and its transparent mode stack entirely. Sangoma became just a hardware vendor to us. It was a shock, yet unsurprising, to learn that the Sangoma stack was costing us nearly a whole millisecond. The new stack was around ten microseconds.
As we were looking at other markets we started to explore FPGAs a little more. I’d nearly started with FPGAs instead of the TopSpin InfiniBand to Ethernet IP approach. I’d been looking at this for some time and reached out to an FPGA company called Celoxica back in 2004 to learn about their technology. When I started this accidental HFT firm I asked Celoxica to quote on a project for getting UDP Ethernet data into a box. Processing market data was a new idea to them. They investigated and came back. Celoxica had a part of a UDP / Ethernet solution they were using in an embedded car system in Germany that they could repurpose. We scoped it out a little but it became too expensive. Years later I was talking to one of the CTOs from a large Wall Street bank – well, he was mid-town based – and he said he had started talking to Celoxica about market data around the same time. So I guess it was not a surprise Celoxica pivoted to market data and that became a thing for them. Their Handel-C was quite beautiful but the implementation never lived up to the full promise, sadly. We did eventually bite into FPGA development which included a research foray into Impulse-C. Impulse-C was pretty cool but we went back to VHDL as our work simply fitted that model better.
The new Sangoma homebrew FPGA firmware was working well for us. However, just as Einstein imagined himself riding alongside the light beam we wanted to get on the first bit, electron or photon, coming into the broker. That existed on the optical fibre coming up into the building. This fibre plugged into the Telco’s communications cabinet from which the E1 modems were subsequently fed. We wanted to get onto the optical line, skip a layer of devices, and leave the E1 copper behind. Nowadays, you can get a multitude of cards that plug FPGAs into a network stack. Back then, we could find nothing straightforward that could do the 622Mbps the Koscom drawing showed us.
So we did our own schematic and PCB layout to build our own simple PCIe network board. It was direct SFPs to Xilinx FPGA with nothing much else, very simple. Previously we’d only produced some T1/E1 tap boards we kitted up into some small black plastic housing that simplified our tap infrastructure. Those tap circuit boards cost only some tens of cents each to make before being soldered. They saved us a lot of grief as we no longer needed the powered NetOptics taps and our cabling was simpler and less obtrusive. These FPGA boards were simple for FPGA boards but complex for us. We took up our new FPGA NICs, some passive NetOptics fibre taps to Korea. After midnight, when all was quiet, we bumped the taps in and fed our new FPGA boards. We had a signal, but it was unintelligible.
Back in Sydney, the bits were kind of echoing or repeating and we struggled to understand the signal. We eventually figured out the architecture diagram, that was still on the cabinet in Korea, was wrong. We were actually getting a 155Mbps STS-3/STM-1 format on an OC-3 carrier. Now we could decode it. It was a joy to behold. We had more speed and could also spot our own orders in the outlines of the data packets, which was fun. Other orders were encrypted and invisible, thankfully. There were a lot more 64kbps channels to scan to find our needed data, so we built some tools to help with that as things changed around a bit more frequently. Eventually, we’d move to our own fibre-based star topology. It all led back to a cabinet near the KRX campus using our FPGA cards for low latency communications, which proved to be successful with the arbitration and co-ordination of eight sites.
Speculation
I wanted to try a new trick with KRX orders. As it was TCP, we could send part of the order down the line before we had the whole thing. It was just a stream of bytes. The extra TCP header was OK as we’d save quite a few bytes overall. However, we had two problems. Firstly, if we didn’t have an order ready to go what would we do? Every N seconds we had to send a heartbeat if the PID wasn’t used. We couldn’t send total rubbish to the exchange as we might attract a warning. As we were behind the firewall, we could only deal with IP packet level stuff and no Ethernet invalidation or checksum tricks would work from here.
Instructing cancellation of an already cancelled or executed order was a valid message. It often happened in the normal course of business. That’s what we did. We randomised the choice of cancellations, so there would be no repetition. We did get queried about the cancels we were sending by one smart broker, so we put in a back-off mechanism: when it was quiet, the trading reverted to heartbeats. All this worked fine on the unencrypted test exchange network, but we still had to solve the problem of the ARIA cipher.
It’s worth noting that with a 1Gbps FIX 4.2 feed, such as used by BATS in the US before 10G, the speculation savings still works if you use FPGAs. For every twenty five bytes at 1G you speculate on, you save 200 nanoseconds. Simple checksum invalidations usually prevent speculations percolating beyond the Ethernet link.
ARIA cipher hacking
I wrote to the university in Seoul that was the keeper of ARIA, and they sent me some 8 and 32-bit C code for the cipher. We took that, broke into enough of the handshake to get the session key, and we could then encipher messages correctly. There were some dodgy aspects of the whole encryption business model as you had to pay a firm a royalty of a few thousand dollars a year to use their official, open-source derived, encryption library. Everyone in Korea was paying for this. Someone was making out like a bandit.
By using our own ARIA bypass, we were a lot faster without the official cipher library. Eventually, we wrote own custom SIMD version that worked even better. Our reverse-engineered encryption allowed our whole trade cycle overhead to be less than just the enforced official encryption overhead.
Now we could finally send a partial order message down the TCP stream. We saved some milliseconds doing this which got eroded to hundreds of microseconds over time as the line speeds increased. The benefit was actually greater than just the stream latency savings. The switches Koscom used were “store and forward switches” back then, so smaller packets also transitioned faster through the whole system. The improvements in timings ended up being a bit better than we expected perhaps due to this.
Today there are many public sources for ARIA and your Korean life can be simpler than ours was.
Shake a tail feather
We also tried some packet fragmentation techniques. A network device might split your packet up into fragments for various reasons. A Unix stack by default will hold onto fragments for sixty seconds and reassemble. If nothing arrives, it will drop them. One idea was to send possible closing packet fragments, a tail feather, then send the correct middle or start fragment, and let the exchange join the packets up. The line rate was so slow there were many hundreds of microseconds to save.
We hacked together some code to test this. Packet fragments didn’t seem to work at first. However, we found after reducing the inter-fragment time to less than two seconds things worked nicely. It looked like the firewall was treating packet fragments as a denial of service attack, or some such, if the gap was too large. It probably should have just not allowed it at all, but hey, who are we to argue. Using this approach, you could have a body of packets waiting at the exchange to match up. The two-second thing was an issue as you’d chew up a lot of valuable bandwidth trying to keep your transient packet cache alive. We had a better idea.
We were already sending the first part of the message in an early packet. Why not send the later part of the packet with the next TCP sequence number plus one and then send the middle part of the sequence out of order with the symbol, price and quantity? That final part of the packet had quite a large user field so we would save an awesome amount of time and gain much more than we were with the speculative send we were already doing. There was a major impediment to this plan.
The ARIA cypher was used in Cipher Block Chaining (CBC) mode. That means the encryption of subsequent bytes relied on the content of the prior ciphertext. As we didn’t know the middle of the packet before a speculative send, we were in trouble.
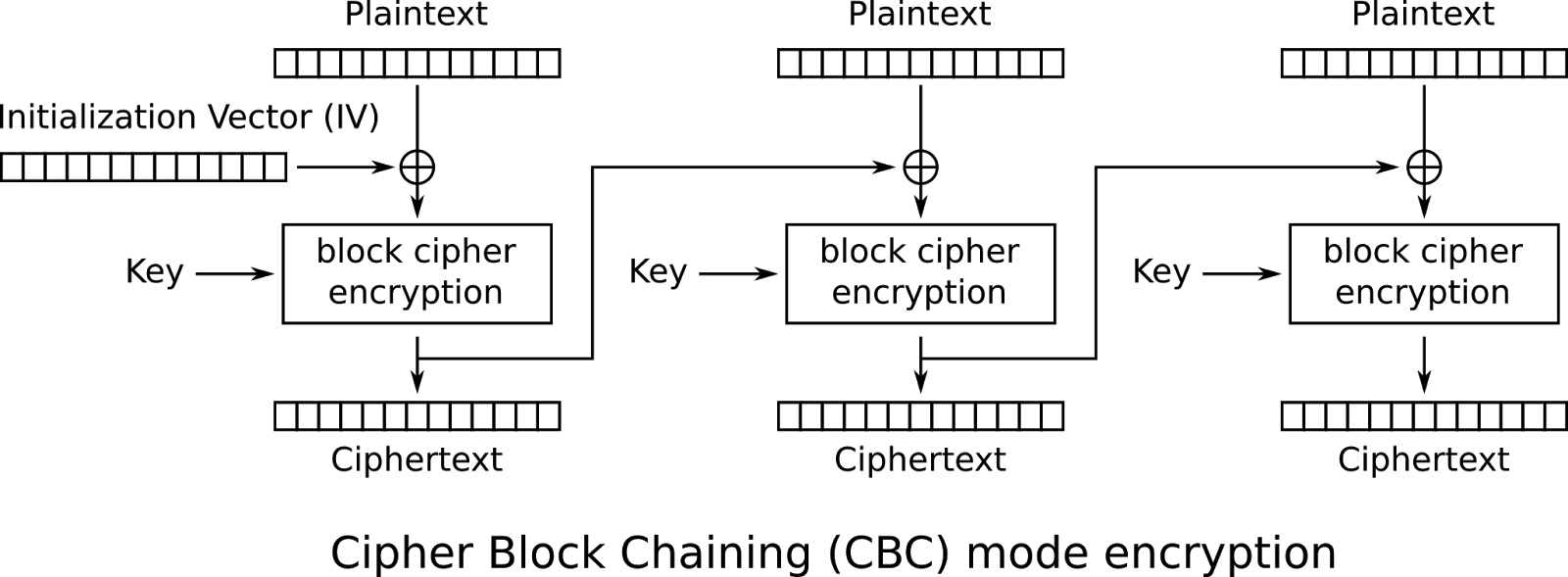 |
| CBC – just add zeros but make sure there are no zeros 😉 |
If the last bytes of an order could be random junk, it wouldn’t matter, as deciphering would turn junk into junk, which would be acceptable. Unfortunately, there had to be some real data after the big user-defined field at the tail of the packet. Also, the KRX was kind of scared of nulls, or zeros, in the packets. They didn’t allow this. Koscom seemed to have an unreasonable fear that something may blow up, or prematurely terminate if a zero byte lived in a packet. They were OK with having a bunch of zeros in the ciphertext as this they could not control. Ciphertext with zeros kind of forces a mini-reset in the cypher chaining due to the CBC XORing with those zeros. That is, enough cypher zeros break the dependence, allowing you to control the subsequent bytes. Those cypher zeros could decipher to anything though, even an illegal zero.
The hack was to force those cypher zeros into the user field and to also keep the middle fragment with a few characters of that same user field. The packets split the user field. You have a better than ninety percent chance the junk you have in the tail user field is non-zero on your first crack. If you check this when preparing your middle packet and you hit a problem, you just cycle through a character or two in the small held out user field in the middle packet, that is the final packet delivered until you’re zero free in the deciphered interpretation of the tail already sent. This hack can save you a large amount of latency.
Machine learning
The most significant improvement we ever had though came from none of this low-level trickery. We put a Random Forest (RF) to work as a machine learning layer on the future’s theoretical price. I initially gave that to one of my PhDs at the firm. We had six. He seemed to be a mathematics genius and had a Physics PhD on some kind of singularity-less cosmological model, I think. He was a good friend who I also hired years prior for a project and taught him C++. He had lectured C++ at a university in Queensland subsequently. I also hired one of his PhD students he had taught C++. We had some funny generations of C++ learning floating around. I tasked him with getting a machine learning layer done using an RF. He came back after a couple of months and showed me all the stuff he had tried that didn’t work and then explained to me why it would never work, and why it was a waste of time.
My own postgraduate degree was in this kind of subject, so I figured I’d better do it myself. I grabbed a tool, OpenDT v5.2, that would run on MPI across our homebrew microATX board cluster. It had grown to over a thousand cores with boards sitting in rubber bumps glues on to particle board with power supplies sitting on grating shelves above the board. Two weeks of OpenDT on the cluster helped me dial in a decent solution. I could replicate the result using code derived from Brieman’s original RF source. I kicked this over the fence to Mr. L. to bring into production. This was the same guy that had sent a thousand orders to the KRX that nearly wiped us out. He was a decent programmer, despite that early hiccough, and he had it in production in another two weeks. We saw an immediate lift of around a third in profit. It was a good month’s work.
Further improvements and adjustments to the ML gave greater returns. We became quite dependent on this. Making the forest a low latency forest was hard work, as accessing huge amounts of memory in a random order is anathema to being low-latency. In later firms, I did much better on that score. After about a year or so, if we turned the ML off, we’d make no money. It was never properly examined if this was due to our strategy adapting to the ML or if latency alone was no longer enough to win. I suspect the later. I’d seen clever players, like Jump, unload dozens of servers in Korea and they were not using them for idling. There was likely a fair amount of ML in the air.
One mature way to think of ML is that it is a just a latency reduction technique. It buys you time by trading in uncertainty. You trigger sooner, but you might be wrong. Even the best non-atomic arbs are uncertain in execution though. The proper way to think about ML, I feel, is that it just provides further feature points in that spectrum that is dimensioned by latency and uncertainty.
Canaries
Another hack I should probably mention is a common one. It is that of the canary. The CME was castigated by many some time ago as the Wall Street Journal revealed some traders were getting order executions back before market data and this speed differential was giving them some advantage over market data subscribers. This was a fallacious argument as the two speeds can never be the same. It is quite the normal thing for extra processing to cause the market data to be slower than the order return channel.
There are a few exchanges where this is not the case. Nasdaq was one of the early exchanges to have market data faster than order notification. That was a trap for young players in itself. Not many expect or design for that.
In my early days at the KRX, you could have a canary go off over a second before the market data arrived. Remember the canary is a limit order you’ve placed at depth and not at best. So the market has traded through and it is now trading at a new price level. Your canary is snuffed out, allowing you to know this an entire second before the rest of the market. If you can’t make money from that, you’d have to have rocks in your head. Well, I found a few rocks in my head.
It got bizarre. Sometimes, the lead in price was so great that you could see the price going up and then down. The naive thing of buying before it went up could get you into trouble as it then went down. You’d have to try to time those events so you could buy and then sell your deltas. Too much knowledge was a funny problem to have. We integrated this into our data feed. One of the guys, Mr. F., named this a “starpower” event, after the Mario Bros. It was a lot of fun to get a star power event.
Jitter matters, not latency
You may recall how the integration of the three exchanges in the KRX didn’t really affect the KOSPI futures and options as they were already trading in Seoul in the KSE’s domain. The KRX shut down Busan, with everything moving to Seoul. Politically, that didn’t work well for the government. The Busan centre eventually opened up again.
A lot of money had been spent on data centres by banks and brokers in Seoul. To mitigate this, market data was sent to Seoul for use and then bounced back to Busan for use in the proximity centre there. This was a mess. Only now, in 2016, has the KRX moved to have local data in Busan. Prior to having local data in 2016, the best solution was to put your market data in Seoul and pipe data down to ordering infrastructure in Busan. Costly and inefficient. Various firms, like us, considered getting their own lines between Seoul and Busan. Koscom banned that to keep the revenue. You could only buy – various expensive – lines from Koscom, so brokers did. Generally, you were fighting over lines that were 2.9 or 3.1 milliseconds in speed for the link. Quite slow for a 300km direct, or a windy 400km drive. There have been a couple of KT-based part microwave solutions pop up though in the last couple of years.
At the same time, the KRX moved from being the largest commercial HP/Compaq/Tandem platform in the world to an AIX platform running on IBM PowerPC architecture. Before the move, we were getting around 11-12 ms round trip times (RTT) on the order lines with a jitter of about 130 ms. After the Busan move, RTTs blew out to over 20ms but the jitter dropped to around 30ms. Even though the latency doubled, the jitter reduction made being fast more productive.
This is similar to how CME has reduced jitter with their iLink FPGA-based gateways. Randomness reduces and being fast matters more. That is one version of fair. The difference in Korea was that latency actually increased for the KRX but that is not what you care about as a trader. You care more about certainty. Is my effort worthwhile? The new platform improved our ROI in Korea.
Similarly, I expect the lower jitter, usually as consequence of lower latency exchanges, not just at CME but at exchanges the world over, will continue to polarise those into the haves and have-nots of latency. Latency continues to matter even when is not critical.
Competition
It’s worth noting what happened when Getco came to Korea. I didn’t know much about them in a practical sense. The first I heard was lots of complaints from brokers. Getco drives a pretty hard bargain and it works for them. It certainly worked in Korea. There were rumours of terrific brokerage deals so brokers could gain market share. Not too dissimilar to the CIBC Canadian deal perhaps? Getco was rumoured to have negotiated a very low fixed fee, perhaps of only a few thousand dollars, for Canadian stock trading to provide market share notoriety for CIBC.
I began to hear reports of Getco taking a 5% market share. Someone else told me it was closer to 15%. A lot of brokers were complaining about their customers no longer getting enough trades. The community was getting quite vocal and upset about this Getco arrival. But we didn’t experience a blip. No tremors at all. We were sufficiently diversified and deploying strategies that others weren’t, so not many could really grasp what we had going on. It did serve as a lesson though: Getco displaced people by introducing a better way of trading. Many people get disenfranchised and complain. The press picks it up. You start reading stories about how unfair the market is. It’s not. It’s just the sore echo of the disenfranchised you hear. This is the sad story you hear in the markets time and time again as traders fight over efficiencies and the inefficient get weeded out. The market improves, but the complaints get louder.
The stuff I was doing was working and was acceptable in Korea, and it would have been acceptable in many other countries. But not at Eurex, as an example. Regulations vary. If you’re an asset manager, you may now realise, you don’t want to play this game. It’s a tough competition, with hundreds of traders like me constantly cooking up strategies. But you do not need to play. A high-frequency trader like me is focused on the next tick. That’s all we care about. We spend stupid amounts of resources trying to out-compete our fellow HFTs for that next tick. I don’t care about your alpha. It’s beyond my horizon. It’s beyond my care.
I lose a lot and I win a lot during a day. I left the accidental HFT firm I founded in May 2005 in January 2011. We’d had only eight down days in all that time by our main trading profit measure. Four were less than 1,000 USD and all were less than 10,000 USD. Not quite as good as Virtu’s famous 1 in approximately 1200 days from their IPO documents, but I’ll take it. Remember though, that’s a lot of trades with a not-so-high individual success rate. We only made a fraction of the spread, typically 10%, but perhaps 5% on a bad day and 20% on a good day. Those days after expiry sometimes gave us 50%, as many traders took breaks from the market on post expiry Fridays each month.
It is simply the law of big numbers that lets an HFT make money every day. That same law dictates that if we lose enough edge, we either end up unable to trade, or we lose money every day. HFTs often disappear. It’s a tough industry, plumbing the depths of market infrastructure and microstructure to improve its efficiency. It’s a thankless task where people don’t understand that today’s rooster may turn into a feather duster when a company like Getco comes to town. I’m sure Jump’s arrival also caused a few feather dusters to appear.
Korea is a fun place, as the KRX infrastructure is still messy. There is a lot more that can be done with slow, clumsy, and arcane infrastructure. HFTs love mess they can dig into and find edges. It’s not hard, it’s just attention to detail. All complexity is made up of simple things. Funnily enough, HFTs hate co-located exchanges that are low latency with simple messages as it is hard to scramble for an edge. HFTs also like such venues as they know it is unlikely someone else may have an unknown edge on them. You never want to walk into an ambush.
An asset manager’s conclusion
Asset managers: don’t worry about the next tick. Encourage market structures that are competitive, fair, and cheap. Then you can stand back and watch with glee why those HFT firms kill each other fighting for the lowest spread. This enables their liquidity to serve you, despite their motivations. After all, only buying higher and selling lower (i.e. narrowing the real spread) works to compete for the next tick. That is not a recipe for easy HFT money.
HFTs are scared of asset managers. Asset managers carry a big information stick that kills HFTs with adverse selection. Big orders move prices which interferes with a market maker’s ability to earn the spread. Asset managers think differently. A hit is a wanted trade, even if adversely selected, and a miss is a cost that you now need to chase for your model. A hit for an HFT is a risk, adverse selection is a disaster, and a miss is a shrug.
An asset manager should use algos and the magic of market efficiency to drive sensible execution outcomes. You don’t want to hire twenty people just to fight for queue position on the next tick. Worry more about machine learning asset managers automating away your alpha. Worry about disenfranchised HFTs giving up and going long-term to compete directly against you. I see both happening already.
Some, but not many, brokers are delivering competitive solutions. Things seem a little stale though. A huge asset manager with a large team may be able to get some value out of rolling their own algorithms and DMA platform so they can trade more aggressively and frequently, just as floundering HFTs look further out on their time horizon. Beware: it’s a slippery slope out there.
Ariel Silahian
http://www.sisSoftwareFactory.com
https://twitter.com/sisSoftware
Keywords: #hft #quants #forex #fx #risk $EURUSD $EURGBP $EURJPY #fintech


